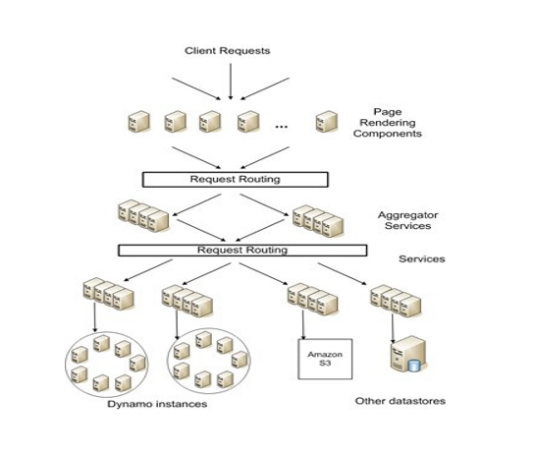
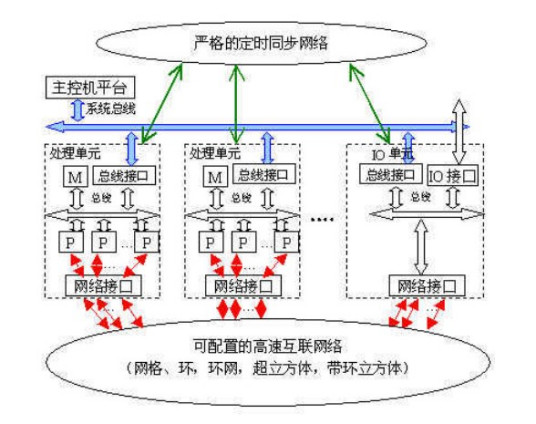
分布式算法内容介绍分布式计算简单来说,是把一个大计算任务拆分成多个小计算任务分布到若干台机器上去计算,然后再进行结果汇总
目的在于分析计算海量的数据,从雷达监测的海量历史信号中分析异常信号(外星文明),淘宝双十一实时计算各地区的消费习惯等
海量计算最开始的方案是提高单机计算性能,如大型机,后来由于数据的爆发式增长、单机性能却跟不上,才有分布式计算这种妥协方案
因为计算一旦拆分,问题会变得非常复杂,像一致性、数据完整、通信、容灾、任务调度等问题也都来了
举个例子,产品要求从数据库中100G的用户购买数据,分析出各地域的消费习惯金额等
如果没什么时间要求,程序员小明就写个对应的业务处理服务程序,部署到服务器上,让它慢慢跑就是了,小明预计10个小时能处理完
后面产品嫌太慢,让小明想办法加快到3个小时
平常开发中类似的需求也很多,总结出来就是,数据量大、单机计算慢
如果上Hadoop、storm之类成本较高、而且有点大才小用
当然让老板买更好的服务器配置也是一种办法
分布性和并发性是分布式算法的两个最基本的特征
分布式系统的执行存在着许多非稳定性的因素
由于这些多方面的差异,导致分布式算法的设计和分析,较之集中式算法来讲,要复杂得多,也困难得多
所谓分布式算法,就是指在完成乘加功能时通过将各输入数据每一对应位产生的运算结果预先进行相加形成相应的部分积,然后再对各部分进行累加形成最终结果
而传统算法则是等到所有乘积结果之后再进行相加,从而完成整个乘加运算
以上内容由大学时代综合整理自互联网,实际情况请以官方资料为准。