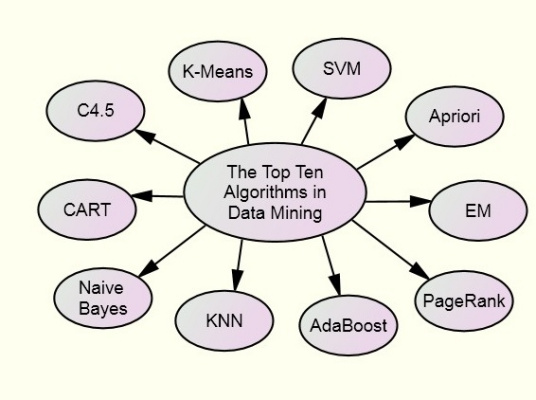
数据挖掘算法算法分类1:C4.5C4.5就是一个决策树算法,它是决策树(决策树也就是做决策的节点间像一棵树一样的组织方式,其实是一个倒树)核心算法ID3的改进算法,所以基本上了解了一半决策树构造方法就能构造它
决策树构造方法其实就是每次选择一个好的特征以及分裂点作为当前节点的分类条件
C4.5比ID3改进的地方时:ID3选择属性用的是子树的信息增益(这里可以用很多方法来定义信息,ID3使用的是熵(entropy)(熵是一种不纯度度量准则)),也就是熵的变化值,而C4.5用的是信息增益率
也就是多了个率嘛
一般来说率就是用来取平衡用的,就像方差起的作用差不多,比如有两个跑步的人,一个起点是100m/s的人、其1s后为110m/s;另一个人起速是1m/s、其1s后为11m/s
如果仅算加速度(单位时间速度增加量)那么两个就是一样的了;但如果使用速度增加率(速度增加比例)来衡量,2个人差距就很大了
在这里,其克服了用信息增益选择属性时偏向选择取值多的属性的不足
在树构造过程中进行剪枝,我在构造决策树的时候好讨厌那些挂着几个元素的节点
对于这种节点,干脆不考虑最好,不然很容易导致overfitting
对非离散数据都能处理,这个其实就是一个个式,看对于连续型的值在哪里分裂好
也就是把连续性的数据转化为离散的值进行处理
能够对不完整数据进行处理,这个重要也重要,其实也没那么重要,缺失数据采用一些方法补上去就是了
2:CARTCART也是一种决策树算法!相对于上着有条件实现一个节点下面有多个子树的多元分类,CART只是分类两个子树,这样实现起来稍稍简便些
所以说CART算法生成的决策树是结构简洁的二叉树
3:KNN(K Nearest Neighbours)这个很简单,就是看你周围的K个人(样本)中哪个类别的人占的多,哪个多,那我就是多的那个
实现起来就是对每个训练样本都计算与其相似度,是Top-K个训练样本出来,看这K个样本中哪个类别的多些,谁多跟谁
4:Naive Bayes(朴素贝叶斯NB)NB认为各个特征是独立的,谁也不关谁的事
所以一个样本(特征值的集合,比如“数据结构”出现2次,“文件”出现1次),可以通过对其所有出现特征在给定类别的概率相乘
比如“数据结构”出现在类1的概率为0.5,“文件”出现在类1的概率为0.3,则可认为其属于类1的概率为0.5*0.5*0.3
5:Support Vector Machine(支持向量机SVM)SVM就是想找一个分类得最”好”的分类线/分类面(最近的一些两类样本到这个”线”的距离最远)
这个没具体实现过,上次听课,那位老师自称自己实现了SVM,敬佩其钻研精神
常用的工具包是LibSVM、SVMLight、MySVM
6:EM(期望最大化)这个我认为就是假设数据时由几个高斯分布组成的,所以最后就是要求几个高斯分布的参数
通过先假设几个值,然后通过反复迭代,以期望得到最好的拟合
7:Apriori这个是做关联规则用的
不知道为什么,一提高关联规则我就想到购物篮数据
这个没实现过,不过也还要理解,它就是通过支持度和置信度两个量来工作,不过对于Apriori,它通过频繁项集的一些规律(频繁项集的子集必定是频繁项集等等啦)来减少计算复杂度
8:FP-Tree(Mining frequent patterns without candidate generation)这个也不太清楚
FP-growth算法(Frequent Pattern-growth)使用了一种紧缩的数据结构来存储查找频繁项集所需要的全部信息
采用算法:将提供频繁项集的数据库压缩到一棵FP-tree来保留项集关联信息,然后将压缩后的数据库分成一组条件数据库(一种特殊类型的投影数据库),每个条件数据库关联一个频繁项集
9:PageRank大名鼎鼎的PageRank大家应该都知道(Google靠此专利发家,其实也不能说发家啦!)
对于这个算法我的理解就是:如果我指向你(网页间的连接)则表示我承认你,则在计算你的重要性的时候可以加上我的一部分重要性(到底多少,要看我自己有多少和我共承认多少个人)
通过反复这样来,可以求的一个稳定的衡量各个人(网页)重要性的值
不过这里必须要做些限制(一个人的开始默认重要性都是1),不然那些值会越来越大越来越大
10:HITSHITS也是一个连接分析算法,它是由IBM首先提出的
在HITS,每个节点(网页)都有一个重要度和权威度(Hubs and authorities,我也忘了具体的翻译是什么了)
通过反复通过权威度来求重要度,通过重要度来求权威度得到最后的权威度和重要度
11:K-MeansK-Means是一种最经典也是使用最广泛的聚类方法,时至今日扔然有很多基于其的改进模型提出
K-Means的思想很简单,对于一个聚类任务(你需要指明聚成几个类,当然按照自然想法来说不应该需要指明类数,这个问题也是当前聚类任务的一个值得研究的课题),首先随机选择K个簇中心,然后反复计算下面的过程直到所有簇中心不改变(簇集合不改变)为止:步骤1:对于每个对象,计算其与每个簇中心的相似度,把其归入与其最相似的那个簇中
步骤2:更新簇中心,新的簇中心通过计算所有属于该簇的对象的平均值得到
k-means 算法的工作过程说明如下:首先从n个数据对象任意选择k 个对象作为初始聚类中心;而对于所剩下其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类;然后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到标准测度函数开始收敛为止
一般都采用均方差作为标准测度函数. k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开
12:BIRCHBIRCH也是一种聚类算法,其全称是Balanced Iterative Reducing and Clustering using Hierarchies
BIRCH也是只是看了理论没具体实现过
是一个综合的层次聚类特征(Clustering Feature, CF)和聚类特征树(CF Tree)两个概念,用于概括聚类描述
聚类特征树概括了聚类的有用信息,并且占用空间较元数据集合小得多,可以存放在内存中,从而可以提高算法在大型数据集合上的聚类速度及可伸缩性
BIRCH算法包括以下两个阶段:1)扫描数据库,建立动态的一棵存放在内存的CF Tree
如果内存不够,则增大阈值,在原树基础上构造一棵较小的树
2)对叶节点进一步利用一个全局性的聚类算法,改进聚类质量
由于CF Tree的叶节点代表的聚类可能不是自然的聚类结果,原因是给定的阈值限制了簇的大小,并且数据的输入顺序也会影响到聚类结果
因此需要对叶节点进一步利用一个全局性的聚类算法,改进聚类质量
13:AdaBoostAdaBoost做分类的一般知道,它是一种boosting方法
这个不能说是一种算法,应该是一种方法,因为它可以建立在任何一种分类算法上,可以是决策树,NB,SVM等
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)
其算法本身是通过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值
将修改过权值的新数据集送给下层分类器进行训练,最后将每次训练得到的分类器最后融合起来,作为最后的决策分类器
使用adaboost分类器可以排除一些不必要的训练数据,并将关键放在关键的训练数据上面
14:GSPGSP,全称为Generalized Sequential Pattern(广义序贯模式),是一种序列挖掘算法
对于序列挖掘没有仔细看过,应该是基于关联规则的吧!网上是这样说的:GSP类似于Apriori算法,采用冗余候选模式的剪除策略和特殊的数据结构-----哈希树来实现候选模式的快速访存
GSP算法描述:1)扫描序列数据库,得到长度为1的序列模式L1,作为初始的种子集
2)根据长度为i 的种子集Li ,通过连接操作和修剪操作生成长度为i+1的候选序列模式Ci+1;然后扫描序列数据库,计算每个候选序列模式的支持度,产生长度为i+1的序列模式Li+1,并将Li+1作为新的种子集
3)重复第二步,直到没有新的序列模式或新的候选序列模式产生为止
产生候选序列模式主要分两步:连接阶段:如果去掉序列模式s1的第一个项目与去掉序列模式s2的最后一个项目所得到的序列相同,则可以将s1与s2进行连接,即将s2的最后一个项目添加到s1中
修切阶段:若某候选序列模式的某个子序列不是序列模式,则此候选序列模式不可能是序列模式,将它从候选序列模式中删除
候选序列模式的支持度计算:对于给定的候选序列模式集合C,扫描序列数据库,对于其中的每一条序列s,找出集合C中被s所包含的所有候选序列模式,并增加其支持度计数
15:PrefixSpan又是一个类似Apriori的序列挖掘
其中经典十大算法为:C4.5,K-Means,SVM,Apriori,EM,PageRank,AdaBoost,KNN,NB和CART
以上内容由大学时代综合整理自互联网,实际情况请以官方资料为准。