Hadoop应用程序Hadoop 的最常见用法之一是 Web 搜索
虽然它不是唯一的软件框架应用程序,但作为一个并行数据处理引擎,它的表现非常突出
Hadoop 最有趣的方面之一是 Map and Reduce 流程,它受到Google开发的启发
这个流程称为创建索引,它将 Web爬行器检索到的文本 Web 页面作为输入,并且将这些页面上的单词的频率报告作为结果
然后可以在整个 Web 搜索过程中使用这个结果从已定义的搜索参数中识别内容
MapReduce最简单的 MapReduce应用程序至少包含 3 个部分:一个 Map 函数、一个 Reduce 函数和一个 main 函数
main 函数将作业控制和文件输入/输出结合起来
在这点上,Hadoop 提供了大量的接口和抽象类,从而为 Hadoop应用程序开发人员提供许多工具,可用于调试和性能度量等
MapReduce 本身就是用于并行处理大数据集的软件框架
MapReduce 的根源是函数性编程中的 map 和 reduce 函数
它由两个可能包含有许多实例(许多 Map 和 Reduce)的操作组成
Map 函数接受一组数据并将其转换为一个键/值对列表,输入域中的每个元素对应一个键/值对
Reduce 函数接受 Map 函数生成的列表,然后根据它们的键(为每个键生成一个键/值对)缩小键/值对列表
这里提供一个示例,帮助您理解它
假设输入域是 one small step for man,one giant leap for mankind
在这个域上运行 Map 函数将得出以下的键/值对列表 :(one,1)(small,1) (step,1) (for,1) (man,1)(one,1) (giant,1) (leap,1) (for,1) (mankind,1)如果对这个键/值对列表应用 Reduce 函数,将得到以下一组键/值对:(one,2) (small,1) (step,1) (for,2) (man,1)(giant,1) (leap,1) (mankind,1)结果是对输入域中的单词进行计数,这无疑对处理索引十分有用
但是,假设有两个输入域,第一个是 one small step for man,第二个是 one giant leap for mankind
您可以在每个域上执行 Map 函数和 Reduce 函数,然后将这两个键/值对列表应用到另一个 Reduce 函数,这时得到与前面一样的结果
换句话说,可以在输入域并行使用相同的操作,得到的结果是一样的,但速度更快
这便是 MapReduce 的威力;它的并行功能可在任意数量的系统上使用
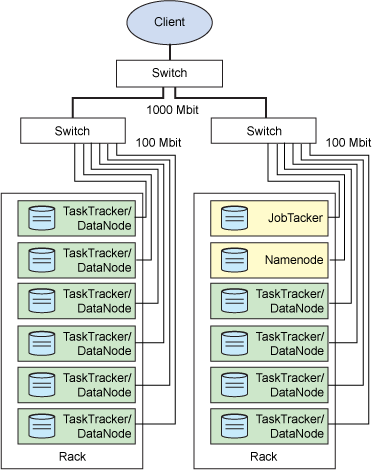
回到 Hadoop 上,它实现这个功能的方法是:一个代表客户机在单个主系统上启动的 MapReduce应用程序称为 JobTracker
类似于 NameNode,它是 Hadoop 集群中唯一负责控制 MapReduce应用程序的系统
在应用程序提交之后,将提供包含在 HDFS 中的输入和输出目录
JobTracker 使用文件块信息(物理量和位置)确定如何创建其他 TaskTracker 从属任务
MapReduce应用程序被复制到每个出现输入文件块的节点
将为特定节点上的每个文件块创建一个唯一的从属任务
每个 TaskTracker 将状态和完成信息报告给 JobTracker
Hadoop 的这个特点非常重要,因为它并没有将存储移动到某个位置以供处理,而是将处理移动到存储
以上内容由大学时代综合整理自互联网,实际情况请以官方资料为准。