SPFA算法原理及证明SPFA算法的全称是:Shortest Path Faster Algorithm,是西南交通大学段凡丁于 1994 年发表的论文中的名字
不过,段凡丁的证明是错误的,且在 Bellman-Ford 算法提出后不久(1957 年)已有队列优化内容,所以国际上不承认 SPFA 算法是段凡丁提出的
为了避免最坏情况的出现,在正权图上应使用效率更高的Dijkstra算法
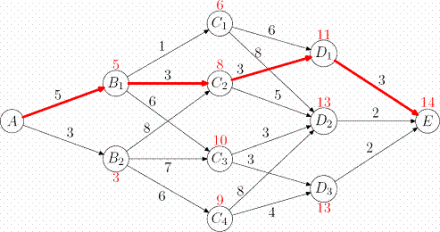
若给定的图存在负权边,类似Dijkstra算法等算法便没有了用武之地,SPFA算法便派上用场了
简洁起见,我们约定加权有向图G不存在负权回路,即最短路径一定存在
用数组d记录每个结点的最短路径估计值,而且用邻接表来存储图G
我们采取的方法是动态逼近法:设立一个先进先出的队列用来保存待优化的结点,优化时每次取出队首结点u,并且用u点当前的最短路径估计值对离开u点所指向的结点v进行松弛操作,如果v点的最短路径估计值有所调整,且v点不在当前的队列中,就将v点放入队尾
这样不断从队列中取出结点来进行松弛操作,直至队列空为止
定理:只要最短路径存在,上述SPFA算法必定能求出最小值
证明:每次将点放入队尾,都是经过松弛操作达到的
换言之,每次的优化将会有某个点v的最短路径估计值d[v]变小
所以算法的执行会使d越来越小
由于我们假定图中不存在负权回路,所以每个结点都有最短路径值
因此,算法不会无限执行下去,随着d值的逐渐变小,直到到达最短路径值时,算法结束,这时的最短路径估计值就是对应结点的最短路径值
实际上,如果一个点进入队列达到n次,则表明图中存在负环,没有最短路径
段凡丁论文中的复杂度证明 (O(kE),k 是小常数)是错误的,在此略去
该算法的最坏时间复杂度为 O(VE)
对SPFA的一个很直观的理解就是由无权图的BFS转化而来
在无权图中,BFS首先到达的顶点所经历的路径一定是最短路(也就是经过的最少顶点数),所以此时利用数组记录节点访问可以使每个顶点只进队一次,但在带权图中,最先到达的顶点所计算出来的路径不一定是最短路
一个解决方法是放弃数组,此时所需时间自然就是指数级的,所以我们不能放弃数组,而是在处理一个已经在队列中且当前所得的路径比原来更好的顶点时,直接更新最优解
SPFA算法有四个优化策略:堆优化、栈优化、SLF和LLL
堆优化:将队列换成堆,与 Dijkstra 的区别是允许一个点多次入堆
在有负权边的图可能被卡成指数级复杂度
栈优化:将队列换成栈(即将原来的 BFS 过程变成 DFS),在寻找负环时可能具有更高效率,但最坏时间复杂度仍然为指数级
SLF:Small Label First 策略,设要加入的节点是j,队首元素为i,若dist(j)
SLF 和 LLL 优化在随机数据上表现优秀,但是在正权图上最坏情况为 O(VE),在负权图上最坏情况为达到指数级复杂度
以上内容由大学时代综合整理自互联网,实际情况请以官方资料为准。