信息增益特征选择在信息增益中,衡量标准是看特征能够为分类系统带来多少信息,带来的信息越多,该特征越重要
对一个特征而言,系统有它和没它时信息量将发生变化,而前后信息量的差值就是这个特征给系统带来的信息量
所谓信息量,就是熵
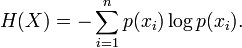
假如有变量X,其可能的取值有n种,每一种取到的概率为Pi,那么X的熵就定义为也就是说X可能的变化越多,X所携带的信息量越大,熵也就越大
对于文本分类或聚类而言,就是说文档属于哪个类别的变化越多,类别的信息量就越大
所以特征T给聚类C或分类C带来的信息增益为IG(T)=H(C)-H(C|T)
H(C|T)包含两种情况:一种是特征T出现,标记为t,一种是特征T不出现,标记为t'
所以H(C|T)=P(t)H(C|t)+P(t')H(C|t‘),再由熵的计算公式便可推得特征与类别的信息增益公式
信息增益最大的问题在于它只能考察特征对整个系统的贡献,而不能具体到某个类别上,这就使得它只适合用来做所谓“全局”的特征选择(指所有的类都使用相同的特征集合),而无法做“本地”的特征选择(每个类别有自己的特征集合,因为有的词,对这个类别很有区分度,对另一个类别则无足轻重)
以上内容由大学时代综合整理自互联网,实际情况请以官方资料为准。



















