高性能计算优化高性能计算(HighPerformanceComputing)是计算机科学的一个分支,主要是指从体系结构、并行算法和软件开发等方面研究开发高性能计算机的技术
随着计算机技术的飞速发展,高性能计算机的计算速度不断提高,其标准也处在不断变化之中
高性能计算简单来说就是在16台甚至更多的服务器上完成某些类型的技术工作负载
到底这个数量是需要8台,12台还是16台服务器这并不重要
在定义下假设每一台服务器都在运行自己独立的操作系统,与其关联的输入/输出基础构造都是建立在COTS系统之上
简而言之,讨论的就是Linux高性能计算集群
一个拥有20000台服务器的信息中心要进行分子动力学模拟无疑是毫无问题的,就好比一个小型工程公司在它的机房里运行计算流体动力学(CFD)模拟
解决工作负载的唯一限制来自于技术层面
接下来我们要讨论的问题是什么能直接加以应用
量度(Metrics)性能(Performance),每瓦特性能(Performance/Watt),每平方英尺性能(Performance/Squarefoot)和性能价格比(Performance/dollar)等,对于提及的20000台服务器的动力分子簇来说,原因是显而易见的
运行这样的系统经常被服务器的能量消耗(瓦特)和体积(平方英尺)所局限
这两个要素都被计入总体拥有成本(TCO)之列
在总体拥有成本(TCO)方面取得更大的经济效益是大家非常关注的
议题的范围限定在性能方面来帮助大家理解性能能耗,性能密度和总体拥有成本(TCO)在实践中的重要性
性能的定义在这里把性能定义为一种计算率
例如每天完成的工作负载,每秒钟浮点运算的速度(FLOPs)等等
接下来要思考的是既定工作量的完成时间
这两者是直接关联的,速度=1/(时间/工作量)
因此性能是根据运行的工作量来进行测算的,通过计算其完成时间来转化成所需要的速度
定量与定性从定性的层面上来说这个问题很容易回答,就是更快的处理器,更多容量的内存,表现更佳的网络和磁盘输入/输出子系统
但当要在决定是否购买Linu集群时这样的回答就不够准确了
对Linux高性能计算集群的性能进行量化分析
为此介绍部分量化模型和方法技巧,它们能非常精确的对大家的业务决策进行指导,同时又非常简单实用
举例来说,这些业务决策涉及的方面包括:购买---系统元件选购指南来获取最佳性能或者最经济的性能配置---鉴别系统及应用软件中的瓶颈计划---突出性能的关联性和局限性来制定中期商业计划Linux高性能计算集群模型包括四类主要的硬件组成部分
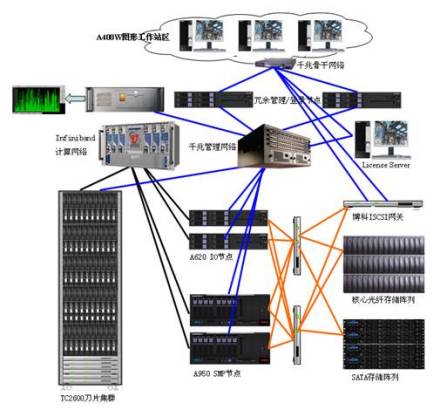
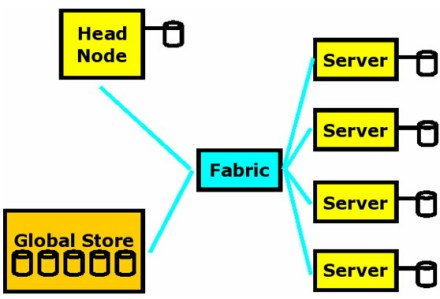
(1)执行技术工作负载的计算节点或者服务器;(2)一个用于集群管理,工作控制等方面的主节点;(3)互相连接的电缆和高度普及的千兆以太网(GBE);(4)一些全局存储系统,像由主节点输出的NFS文件一样简单易用
高性能计算机的衡量标准主要以计算速度(尤其是浮点运算速度)作为标准
高性能计算机是信息领域的前沿高技术,在保障国家安全、推动国防科技进步、促进尖端武器发展方面具有直接推动作用,是衡量一个国家综合实力的重要标志之一
随着信息化社会的飞速发展,人类对信息处理能力的要求越来越高,不仅石油勘探、气象预报、航天国防、科学研究等需求高性能计算机,而金融、政府信息化、教育、企业、网络游戏等更广泛的领域对高性能计算的需求迅猛增长
一个简单量化的运用模型这样一个量化的运用模型非常直观
在一个集群上对既定的工作完成的时间大约等同于在独立的子系统上花费的时间:e1、时间(Time)=节点时间(Tnode)+电缆时间(Tfabric)+存储时间(Tstorage)Time = Tnode + Tfabric + Tstorag这里所说的时间(Time)指的是执行工作量的完成时间,节点时间(Tnode)是指在计算节点上花费的完成时间,电缆时间(Tfabric)是指在互联网上各个节点进行互联的完成时间,而存储时间(Tstorage)则是指访问局域网或全球存储系统的完成时间
计算节点的完成时间大约等同于在独立的子系统上花费的时间:2、节点时间(Tnode)=内核时间(Tcore) +内存时间(Tmemory)这里所说的内核时间(Tcore)指的是在微处理器计算节点上的完成时间
而内存时间(Tmemory)就是指访问主存储器的完成时间
这个模型对于单个的CPU计算节点来说是非常实用的,而且能很容易的扩展到通用双插槽(SMP对称多处理)计算节点
为了使第二套模型更加实用,子系统的完成时间也必须和计算节点的物理配置参数相关联,例如处理器的速度,内存的速度等等
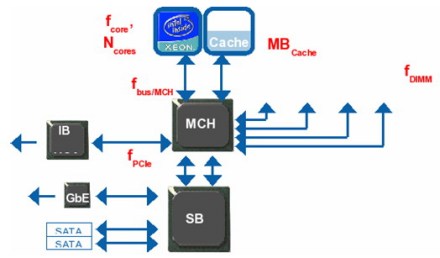
计算节点图示中的计算节点原型来认识相关的配置参数
图示上端的是2个处理器插槽,通过前端总线(FSB-front side bus)与内存控制中心(MCH)相连
这个内存控制中心(MCH)有四个存储信道
同时还有一个Infiniband HCA通过信道点对点串行(PCIe)连接在一起
像千兆以太网和串行接口(SATA)硬盘之类的低速的输入输出系统都是通过芯片组中的南桥通道(South Bridge)相连接的
在图示中,大家可以看到每个主要部件旁边都用红色标注了一个性能相关参数
这些参数详细的说明了影响性能(并非全部)的硬件的特性
它们通常也和硬件的成本直接相关
举例来说,处理器时钟频率(fcore)在多数工作负荷状态下对性能影响巨大
根据供求交叉半导体产额曲线原理,处理器速度越快,相应成本也会更高
高速缓存存储器的体积也会对性能产生影响,它能减少主频所承载的工作负荷以提高其运算速度
处理器内核的数量(Ncores)同样会影响性能和成本
内存子系统的速度可以根据双列直插内存模块频率(fDIMM)和总线频率(fBus)进行参数化,它在工作负荷状态下也对性能产生影响
同样,电缆相互连接(interconnect fabric)的速度取决于信道点对点串行的频率
而其他一些因素,比如双列直插内存模块内存延迟(DIMM CAS Latency),存储信道的数量等都做为次要因素暂时忽略不计
使用的性能参数在图示中标明的6个性能参数中,保留四个和模型相关的参数
首先忽略信道点对点串行的频率(fPCIe),因为它主要影响的是电缆相互连接(interconnect fabric)速度的性能,这不在范围之列
接下来注意一下双列直插内存模块频率(fDIMM)和总线频率(fBus)会由于内存控制中心(MCH)而限于固定比率
使用的双核系统中,这些比率最具代表性的是4:5, 1:1, 5:4
一般情况下只会用到其中的一个
高速缓存存储器的体积非常重要
在这个模型中保留这个参数
内核的数量(Ncores)和内核频率(fcore)也非常重要,保留这两个参数
高性能计算(HPC)模型 这第二个模型的基本形式在计算机体系研究领域已经存在了很多年
A普通模式是:(3) CPI = CPI0 + MPI * PPM这里的CPI指的是处理器在工作负荷状态下每执行一个指令的周期
CPI0是指内核CPI,MPI I则是指在工作负荷状态下高速缓存存储器每个指令失误的次数(注释:在高性能计算领域,MPI主要用于信息传递界面,在此处主要是指处理器构造惯例),PPM是指以处理器时钟滴答声为单位对高速缓存存储器每个指令失误的次数的记录
第二和第三个方程式相互吻合
这第一个术语代表的是处理器,第二个术语代表的是内存
可以直观的看到,假设每项工作下执行的P指令的工作负荷与代表处理器的频率的内核频率(每秒钟处理器运行周期的单位)再与方程式(3)相乘,就得到了方程式(4):Tnode = (CPIo * P) * (1 / fcore) + (MPI * P) * PPM * (1 / fcore)在这里要注意(CPIo * P)是以每项工作分配下处理器的运行周期为单位,对微处理器架构上运行的既定工作负荷通常是个恒量
因此把它命名为α
(处理器周期本身无法对时间进行测算,如果乘以内核的频率就可以得到时间的测算标准
因此Tnode在方程式(4)的右边)
(MPI * P)也是同理
对于既定工作负荷和体系结构来说它也是个恒量,但它主要依赖于高速缓存存储器的体积
我们把它命名为M(MBcache)
而PPM是指访问主存的成本
对于既定的工作负荷来说,通常是个固定的数字C
PPM乘以内存频率和总线频率的比值(fcore / fBus)就从总线周期(bus cycles)转化成了处理器周期
因此PM = C * fcore / fBus
套入M(MBcache)就可以得到:(5) Tnode = α * (1 / fcore) + M(MBcache) * (1 / fbus)这个例子说明总线频率(bus frequency)也是个恒量,方程式(5)可以简化为方程式(6):(6) Tnode = α * (1 / fcore) + β在这里Tcore = α * (1 / fcore),而Tmemory = β(也就是公式2里的术语
我们把这些关键点关联在一起)
首先在模型2里,公式5和公式6都有坚实的理论基础,因为经分析过它是如何从公式3推理而来(它主要应用于计算机体系理论)
其次,这个模型4个硬件性能参数的3个已经包括其中
还差一个参数就是内核数量(Ncores)
用直观的方式来说明内核的数量,就是假设把N个内核看做是一个网络频率上运行的一个内核,称之为N*fcore
那么根据公式(6)我们大致可以推算出:(7) Tcore ~ α / (N*fcore)Tcore~ ( α / N) * (1 / fcore )也可以把它写成:(8) αN = ( α / N)多核处理器的第一个字母Alpha可能是单核处理器的1/N次
通过数学推算这几乎是完全可能的
通常情况下我们是根据系统内核和总线频率(bus frequencies)来衡量计算机系统性能,如公式(5)所阐述的
但是公式(5)的左边是时间单位--这个时间单位指的是一项工作量的完成时间
这样就能更清楚的以时间为单位说明右侧的主系统参数
同时请注意内核的时钟周期τcore(是指每次内核运行周期所需的时间)也等同于(1 / fcore)
总线时钟(bus clock)周期也是同理
(9) Tnode = αN * τcore + M(MBcache) * τBus这个公式的转化也给了一个完成时间的模型,那就是2个基本的自变量τcore和τBus呈现出直线性变化
这对使用一个简单的棋盘式对照表对真实系统数据进行分析是有帮助的
以上内容由大学时代综合整理自互联网,实际情况请以官方资料为准。